

Tired of making you take your video
Looking for the solution to protect your iframes from the robots that remove your videos?
Is your site constantly subject to complaints DMCA ? So look no further, our website is the solution.
The client must enter a captcha or challenge before accessing your video for the purpose of protection against robots.
Quoted directly from their homepage. Every now and then I see people asking if there is a way to block crawlers/scrapers. Probably because of the way DMCA takedown requests are largely automated these days. So with that in mind services like this might seem tempting. Right?
Don't fall for it. Here's a simple fact: you can not prevent your content from being scraped. You can't, protect-iframe.com can't, nobody can. If a human can see or interact with the content so can an automated program. It's one of the reasons that even with millions, if not billions of $ in funding nobody has been able to come up with a bulletproof DRM solution. It's impossible in software and even more impossible on a mostly open platform like the WWW.
I'm sure the owner(s) of protect-iframe.com know this as well. But for them it's an easy way to make money off people who don't know any better. After all, you're embedding their pages, and thus their ads or whatever else they decide to include on their embedded page. So not only are they unable to protect your content, they'll also drive your users away by asking them to complete a captcha or some other challenge. All this while making money off your traffic. So TL;DR: don't use them.
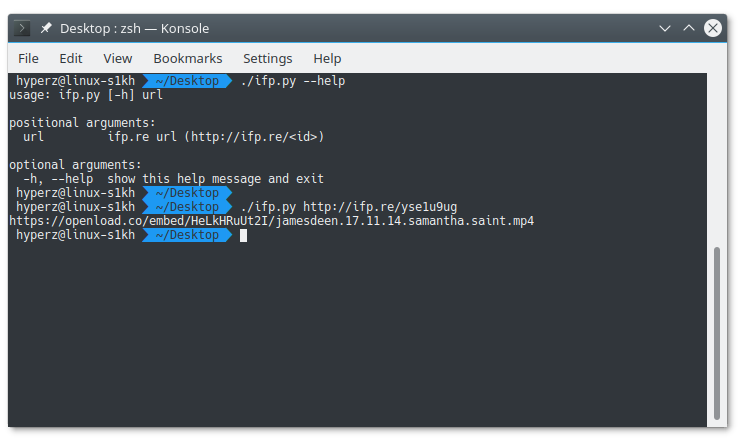
And just to drive the point home, here's a simple scraper that scrapes the real link from one of their "protected" links:
Code:
#!/usr/bin/python3
from argparse import ArgumentParser
import requests
import re
def scrape_link(url: str) -> str:
regex = re.search(r'ifp\.re/(?P<url_id>[^/\s]+)$', url)
if regex is not None:
url_id = regex.group('url_id')
headers = {'Referer': url, 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:56.0) Gecko/20100101 Firefox/56.0'}
resp = requests.get(f'http://ifp.re/embed.php?u={url_id}&d=ifp.re', headers=headers)
results = re.findall(r'//ifp\.re/assets/js/jquery-min\.php\?id=\d+', resp.text, re.M)
if results:
# NOTE: could also use https://github.com/beautify-web/js-beautify/blob/master/python/jsbeautifier/unpackers/packer.py
resp = requests.post('http://jsunpack.jeek.org/', {
'urlin': 'http:' + results[0],
'filename': '',
'referer': resp.url,
'desc': '',
})
results = re.findall(r'window\.location\.replace\(\'(http[^\']+)\'\)', resp.text, re.M)
return results[0] if results else ''
return ''
if __name__ == '__main__':
ap = ArgumentParser()
ap.add_argument('url', help='ifp.re url (http://ifp.re/<id>)')
args = ap.parse_args()
try:
link = scrape_link(args.url)
print(link)
except:
print('ERROR')